numpy.pad()
用来填充数据,可以按指定方式填充numpy数组。
pad(array, pad_width, mode, **kwargs)
返回值:数组
import numpy as np |
为了容易理解,这里用二维数组做示范
((1,1), (1, 1)) 该参数项的前一个(1,1)对应着一维,第二个(1,1)对应着二维。如果是高维数组的话,就往后继续补。拿三维举例,就是((1,1), (1,1), (1,1))
里边的数字1表示在当前维度上的前边和后边分别填充多大形状。也可以选择其他数字
画了个图,方便理解

第3个参数为填充的方式
constant:用连续一样的值填充。有参数项constant_values =(x, y)时前面用x填充,后面用y填充。缺省值为用0填充
edge:用边缘值填充
linear_ramp:边缘递减的填充方式
maximum, mean, median, minimum分别用最大值、均值、中位数和最小值填充
reflect, symmetric:对称填充。前一个是关于边缘对称,后一个是关于边缘外的空气对称
wrap:用原数组后面的值填充前面,前面的值填充后面
当然也可以用其他自定义的方式填充
numpy 中的几种乘法
1). np.dot()
同线性代数的矩阵乘法。
2). np.multiply() 或 *
计算的是矩阵对应位置元素的乘积。
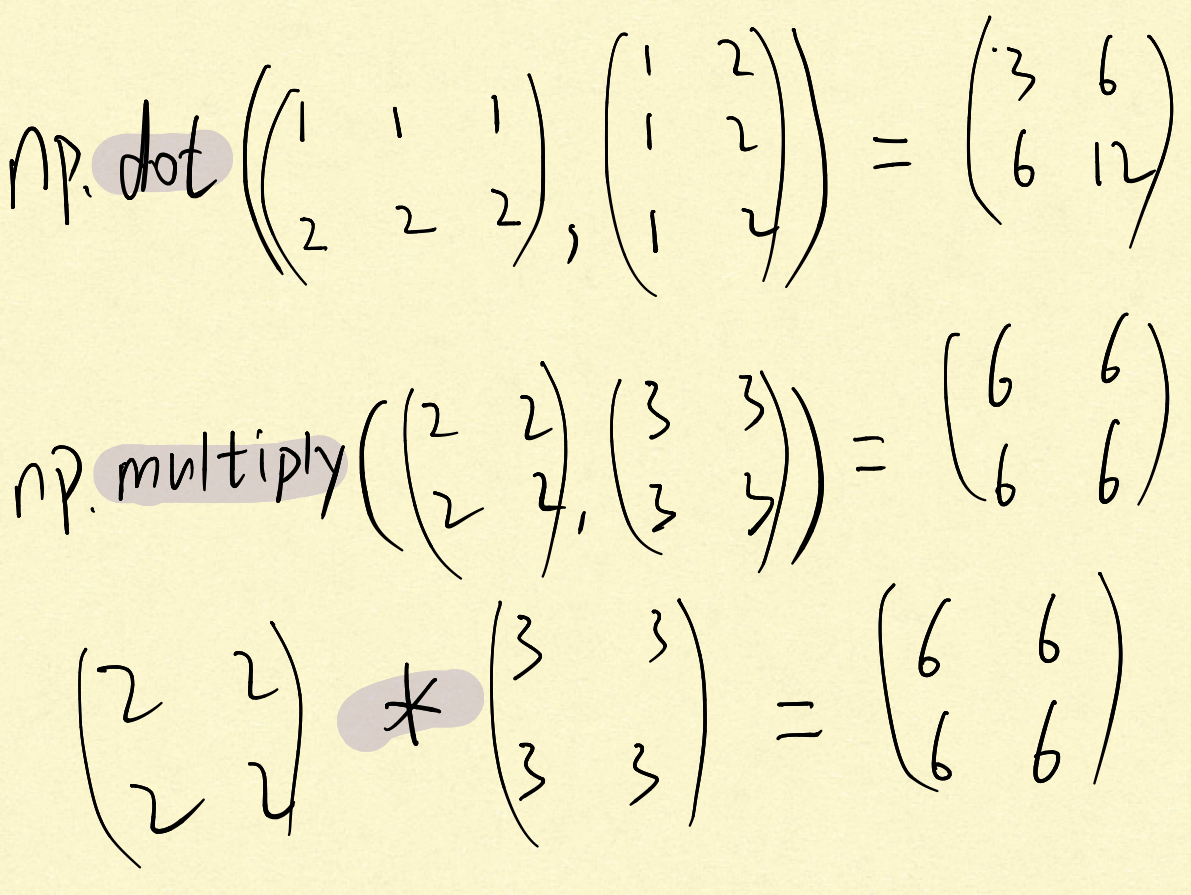
numpy 中 ndarray 和 array区别
我们可以使用np.array()创建一个ndarry。np.array()是一个返回ndarry对象的方法。
numpy 中 shuffle 与 permutation 的区别
两者都是洗牌的功能。区别是:shuffle直接打乱原数据,而permutation是保留原数据顺序,返回一个新的被打乱的数据。
x = np.array([0, 1, 2, 3, 4, 5, 6]) |
np.mean()
求取均值,可以求全部数据均值,也可以按行(列)求取均值
其中参数aixa表示在哪个维度上取均值,0对所有元素取均值
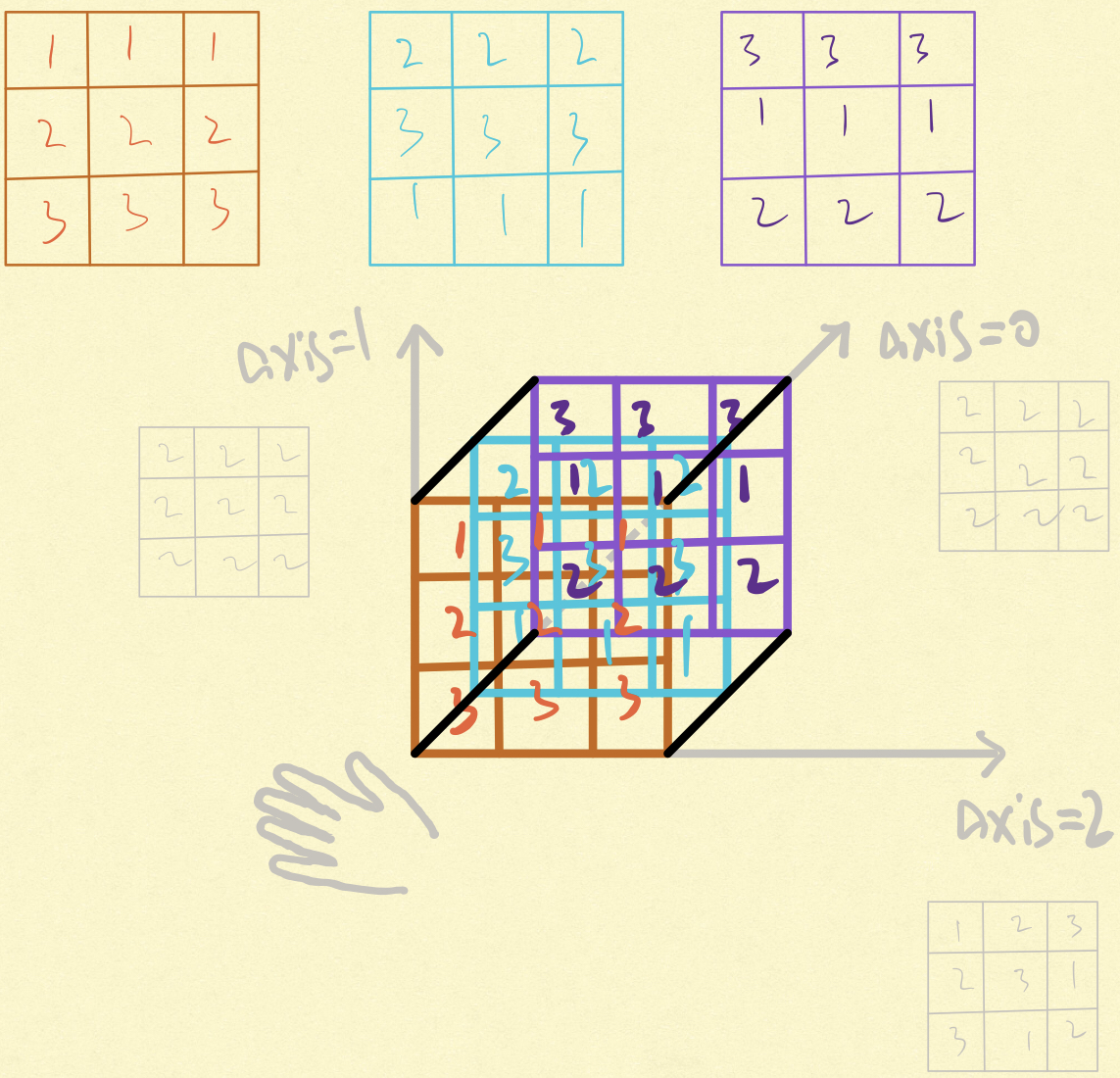
画了个图,hhh
Numpy 中将多维数组转换为一维数组
ravel():如果没有必要,不会产生源数据的副本 。
flatten():返回源数据的副本 。
squeeze():只能对维数为1的维度降维。
除此之外,reshape(-1)也可以「拉平」多维数组。


