3.58
long decode2(long x, long y, long z) { |
3.59
参考本书的 2.3.4 和 2.3.5,其中有两条定理:
- w 位无符号乘法,其结果可能要用 2w 位来表示。但是在 C 语言中 w 位无符号乘法被定义为产生 w 位的值,就是 2w 位的整数乘积的低 w 位表示的值。将一个无符号数截断为 w 位等价于计算模 $2^w$。(这条定理同样适用于补码乘法)。
- 对于无符号数和补码乘法来说,乘法运算的位级表示都是一样的。
现在让我们看这道题目。
将一个 64 位的补码转换为 128 位的补码数,可以通过以下公式实现:$x=2^{64} \cdot x_h + x_l$,其中 $x_h$ 和 $x_l$ 都是 64 位值。
那么如果计算两个 64 位有符号值 x 和 y 的 128 位乘积,就可以这样表示:$x \cdot y=(2^{64} \cdot x_h + x_l) \cdot (2^{64} \cdot y_h + y_l)=2^{128} \cdot x_h \cdot y_l+2^{64} \cdot x_h \cdot y_l+2^{64} \cdot x_l \cdot y_h + x_l \cdot y_l$。
将以上公式套用该题的寄存器,得到如下结果(dest:%rdi,x:%rsi,y:%rdx):$x \cdot y = rdx \cdot rcx \cdot 2^{128} + rdx \cdot rsi \cdot 2^{64} + rcx \cdot rax \cdot 2^{64} + rax \cdot rsi$。
现在得到的结果是 2w=256 位的。要得到 128 位的话,就需要对结果 mod128,得到:$rdx \cdot rsi*2^{64} mod 2^{128}+rcx \cdot rax \cdot 2^{64} mod 2^{128}+rax \cdot rsi$。其中 $rdx \cdot rcx \cdot 2^{128}$ 这项为什么没有了?是因为 $\cdot 2^{128}$ 就是左移 128 位,所以已经超出题目要求的 128 位了。
画了个图:
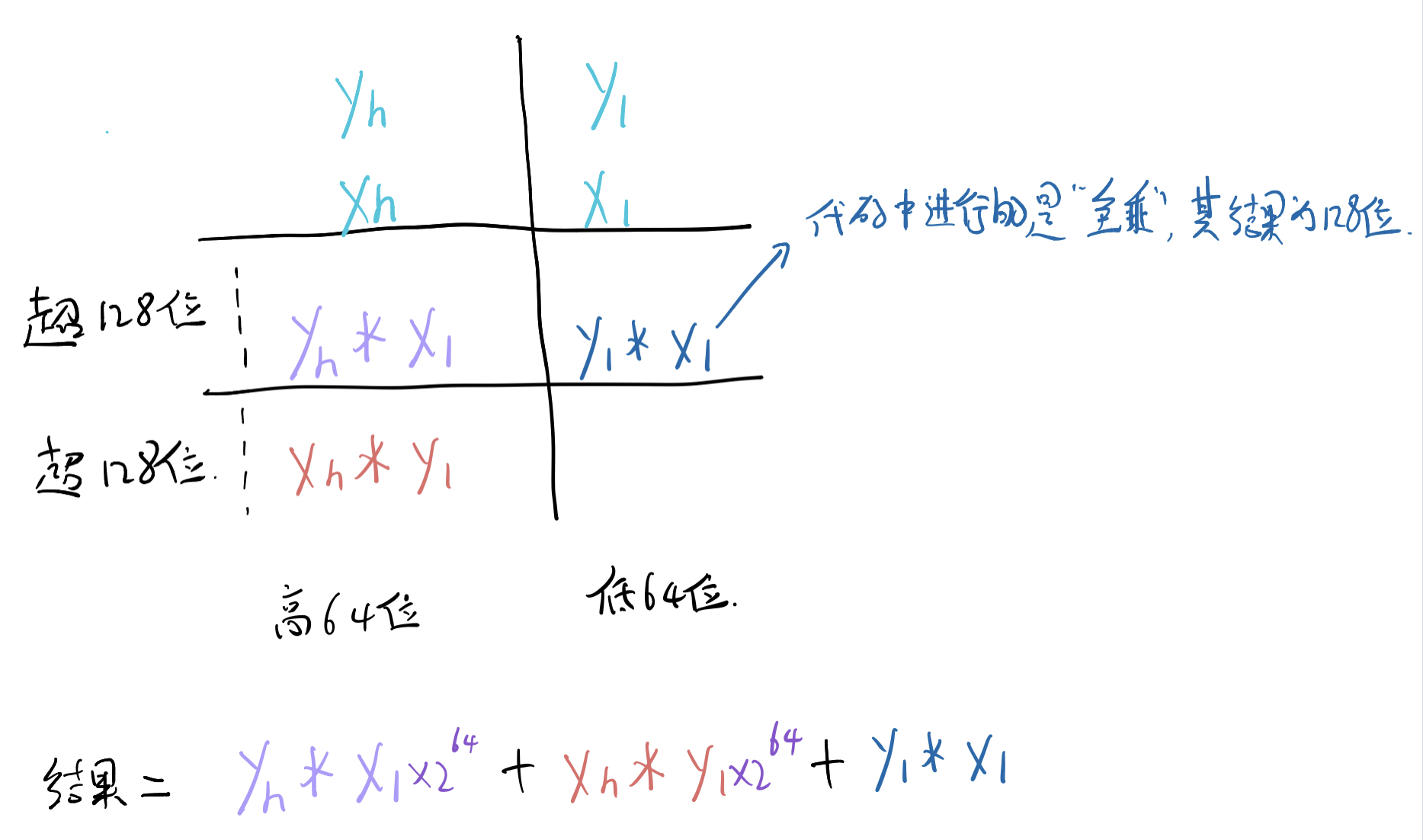
到这原理基本上讲完了,下面看具体的代码。
store_prod |
3.60
x: %rdi |
long loop(long x, long n) { |
3.61
long cread_alt(long *xp) { |
3.62
typedef enum {MODE_A, MODE_B, MODE_C, MODE_D, MODE_E} modee_t; |
3.63
long switch_prob(long x, long n) { |
加餐:(gdb) x/6gx 0x4006F8 指令是什么?
可以使用 examine 命令(简写是 x)来查看内存地址中的值。x 命令的语法如下所示:x/<n/f/u> <addr>。n、f、u 是可选的参数。
n:是一个正整数,表示需要显示的内存单元的个数,也就是说从当前地址向后显示几个内存单元的内容,一个内存单元的大小由后面的 u 定义。
f:表示显示的格式,参见下面。如果地址所指的是字符串,那么格式可以是 s,如果地十是指令地址,那么格式可以是 i。
u:表示从当前地址往后请求的字节数,如果不指定的话,GDB 默认是 4 个 bytes。u 参数可以用下面的字符来代替,b 表示单字节,h 表示双字节,w 表示四字节,g 表示八字节。当我们指定了字节长度后,GDB 会从指内存定的内存地址开始,读写指定字节,并把其当作一个值取出来。
输出格式:
一般来说,GDB 会根据变量的类型输出变量的值。但你也可以自定义 GDB 的输出的格式。例如,你想输出一个整数的十六进制,或是二进制来查看这个整型变量的中的位的情况。要做到这样,你可以使用GDB 的数据显示格式:
x 按十六进制格式显示变量。
d 按十进制格式显示变量。
u 按十六进制格式显示无符号整型。
o 按八进制格式显示变量。
t 按二进制格式显示变量。
a 按十六进制格式显示变量。
c 按字符格式显示变量。
f 按浮点数格式显示变量。
x/6gx 0x4006F8 这条指令就是从地址 0x4006F8 开始,往后读取 6 个,每个 8 字节字的内存。
3.64
3.65
A:%rdx。
B:%rax。
C:M=15。
解释:
由汇编代码可以看到,rdx 每次移动 8,rax 移动 120。可以判断,rdx 表示的是按行移动,rax 表示的是按列移动。
根据 rdx 每次移动 8,可以得出每个数组元素大小为 8。rdx 每次移动 120,说明每行有 120/8=15 个元素,即 M=15。
3.66
解释:
如果通读汇编代码会发现,L3 部分(12-16 行)才是真正的循环体。
.L3 |
3.67
A.
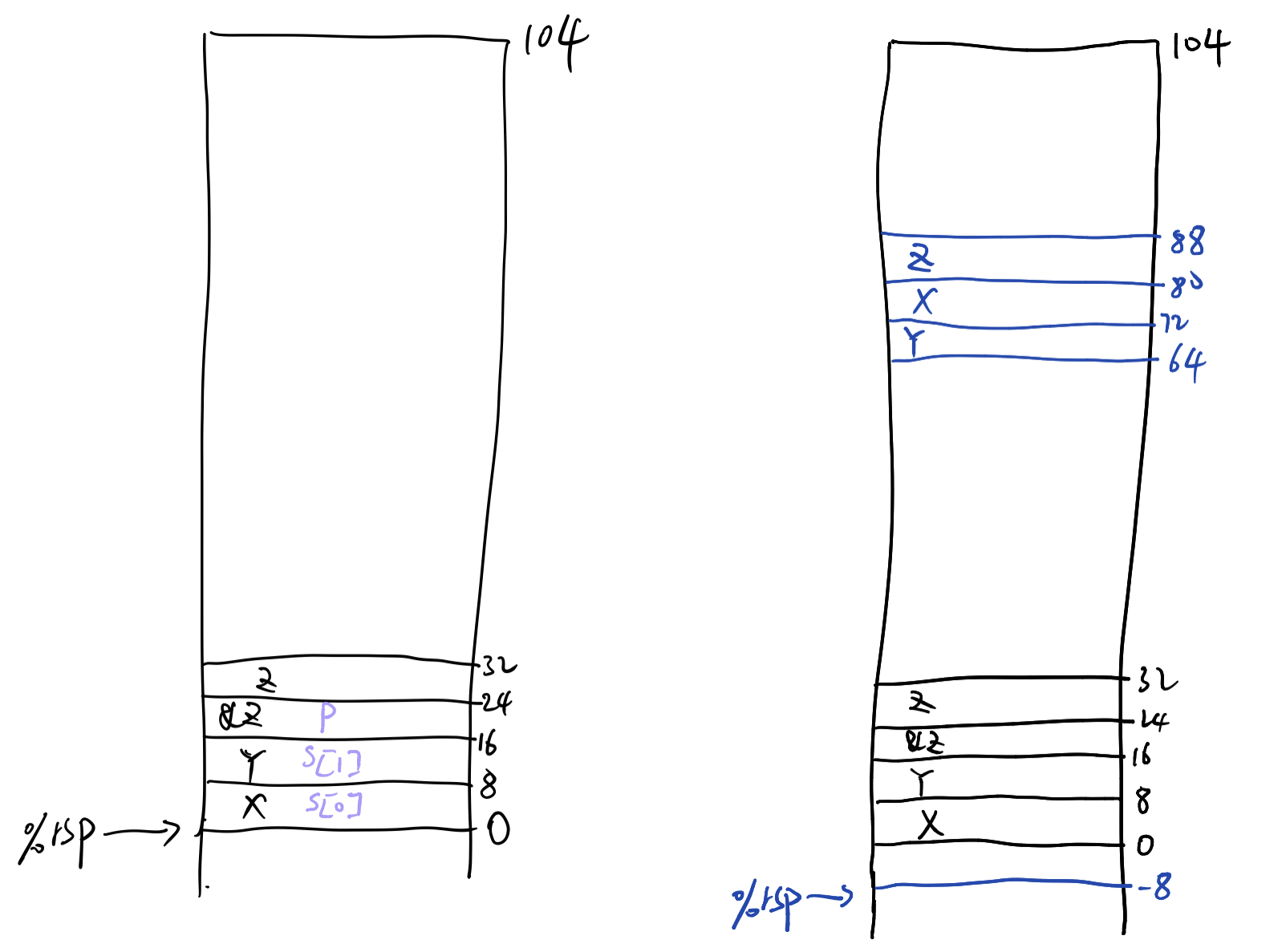
为了便于对比,我把这题和 E 的图放在一起了。
B.
传的是 %rsp+64。
C.
使用 %rsp+C 来访问,其中 %rsp 是基址,常数 C 作为偏移量,取值为 0、8 、16 和 24。
D.
这里要注意,call 指令实际上是执行了两步,1)将程序下一条指令的位置的 IP 压入堆栈中;2)转移到调用的子程序 。
所以执行 call 指令以后,%rsp 的值要减去 8,以用来保存「返回地址」(如 A. 右侧图所示)。
process 通过地址表达式 %rsp+C 来设置结构体 r,C 的取值为 8、16 和 24(注意这里的 %rsp 的值为 -8)。
E.
传递聚合类型的变量,应当传递地址,而不是传递整个数据结构。
3.68
3.69
3.70
3.71
char *fgets(char *s, int n, FILE *stream)
fgets 函数最多将下 n-1 个字符读入到数组 s 中。当遇到换行符时,把换行符读入到数组 s 中,读取过程终止。数组 s 以 \0 结尾。fgets 函数返回数组 s。如果到达文件的末尾或发生错误,返回 NULL。
void *memset(s, c, n)
将 s 中的前 n 个字符替换为 c,并返回 s。
|
3.72
A.
汇编代码第 5 行 leaq 指令计算 8n+30,第 6 行 and 指令向下舍入到最接近 16 的整数。当 n 是奇数时,结果是 8\n+24,当 n 是偶数时,结果是 8*n+16。s1 减去这个值就得到 s2。
B.
将 s2 向下舍入到最接近 16 的倍数。
C.
D.
都向 16 的倍数对齐。
3.73
find_range: |
(这题还没搞懂。)
3.74
3.75
A.
传值使用两个 %xmm 寄存器,一个寄存器表示真部(real),一个寄存器表示虚部(imag)。
B.
返回使用 %xmm0 和 %xmm1 两个寄存器。


